Coordination center and EMS-to-ED operations for routing, readiness, and structured handoff.
MediBridge Ops is designed to replace the highest-value GCC coordination loop first, not to pitch a finished statewide platform. This page supports a workflow-validation conversation around EMS inbound visibility, hospital readiness, structured handoff, and coordination-center operations.
What broke when GCC ended
When GCC call-center operations ended, the coordination problem remained. EMS crews still need current destination-readiness visibility. Hospitals still need earlier, structured inbound handoff. Operational leaders still need one shared picture of delays, acknowledgements, and bottlenecks.
EMS still needs visibility
Crews need usable destination-readiness and diversion context before arrival, not just a phone chase.
Hospitals still need pre-arrival signal
Receiving teams need earlier, more structured inbound information than ad hoc calls alone provide.
Leadership still needs a shared picture
Command-center and operational leaders need acknowledgement, delay, and exception visibility across the loop.
What MediBridge replaces first
- EMS inbound visibility
- Hospital readiness and diversion visibility
- Structured EMS-to-hospital handoff
- Coordination-center oversight, messaging, and audit
The day-one operating loop
This is the highest-value GCC coordination loop first, not the whole platform.
EMS sees destination readiness
Current hospital operating status and destination context before arrival.
EMS initiates structured handoff
Inbound context is shared in workflow rather than relying on phone-only coordination.
Hospital accepts or rejects
Receiving teams acknowledge, review, and respond to the inbound handoff state.
Coordination center intervenes
Delays, rejections, and bottlenecks surface early so the loop stays managed.
Audit preserves the record
The operational loop stays visible for later review, process discipline, and pilot improvement.
Buyer-facing screenshots
Shared operating picture
This view gives command-center and operational leaders a shared picture of coordination state across the loop.
- System status at a glance
- Cross-organization coordination
- Exceptions and bottlenecks surface here

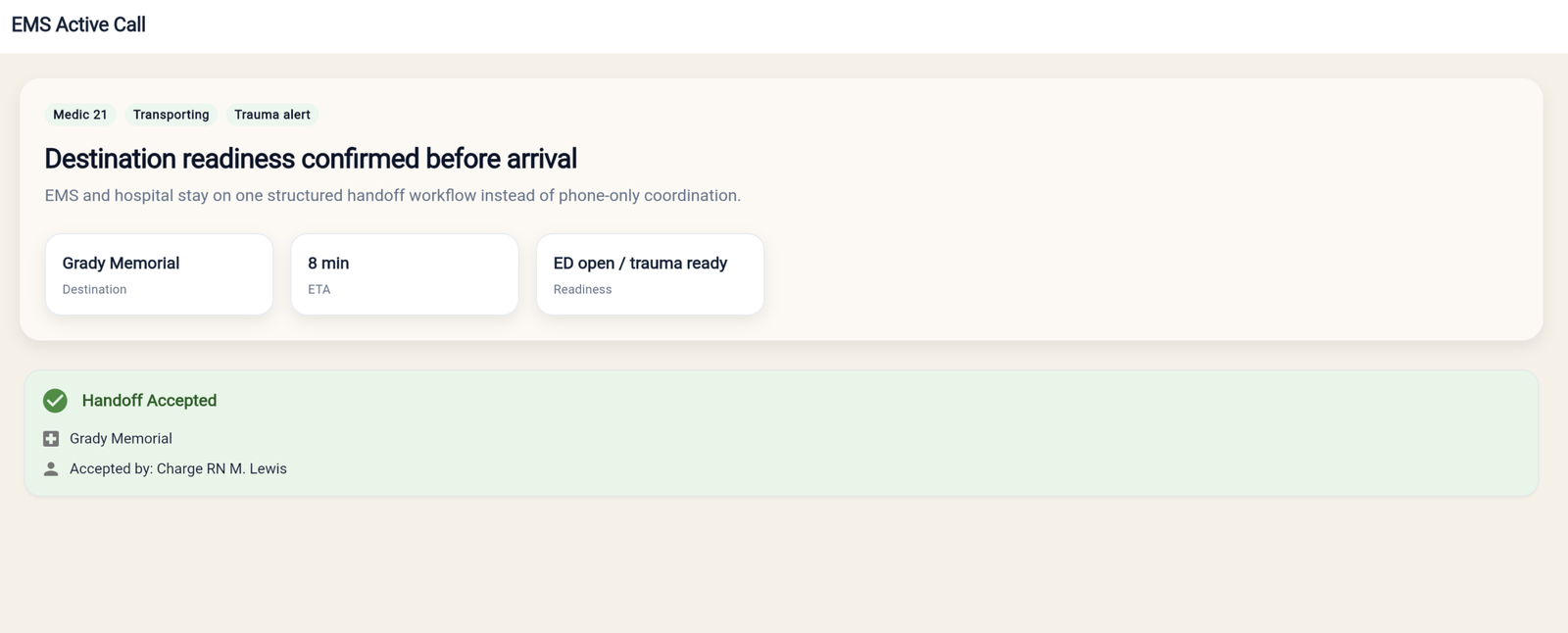
Destination readiness and structured handoff
This is the core wedge. It shows the EMS-side handoff context tied to hospital readiness instead of a disconnected phone-only process.
- Destination readiness before arrival
- Structured handoff instead of phone-only coordination
- EMS and hospital stay on the same workflow
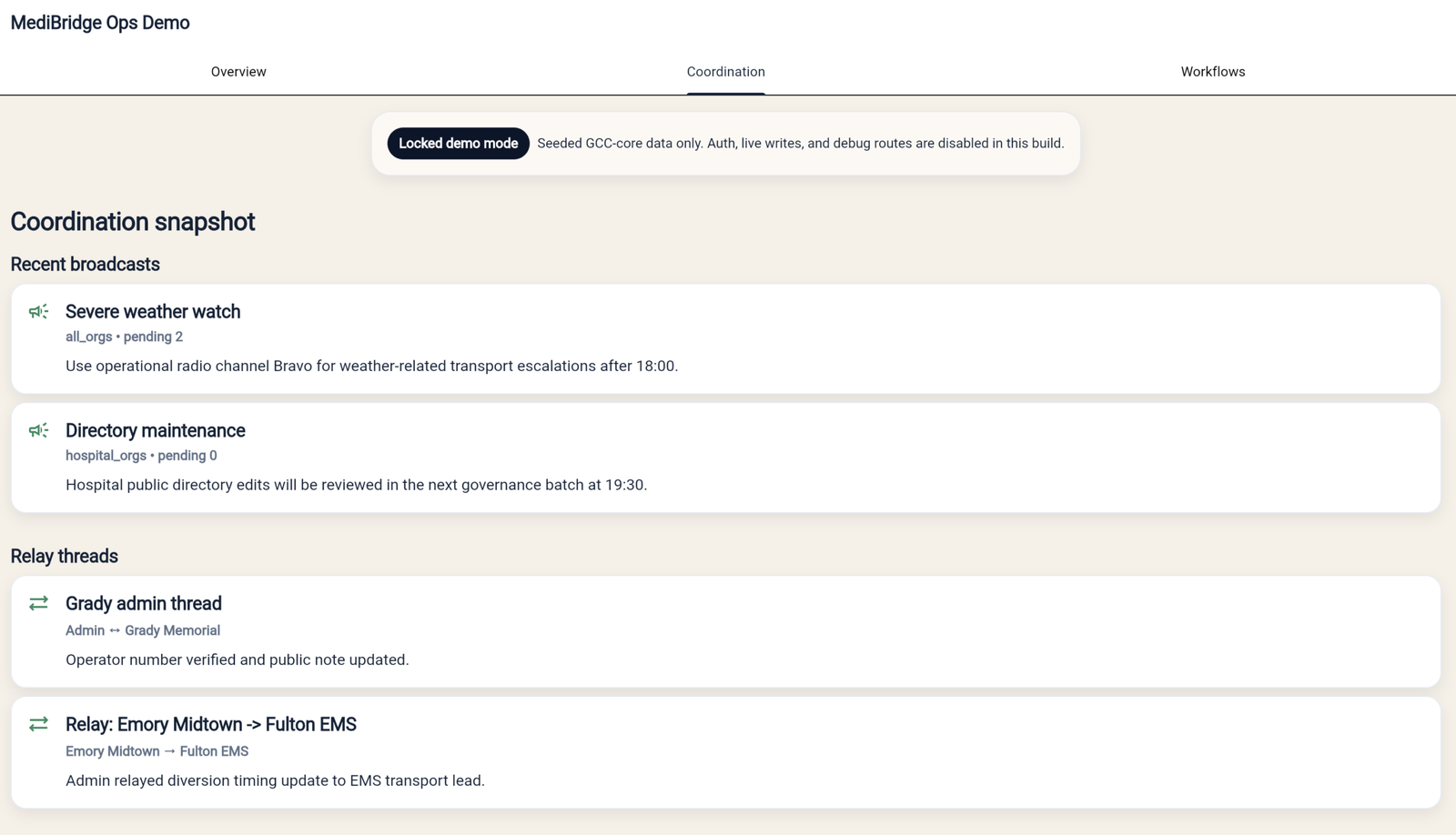
Coordination-center messaging and relay activity
This view shows the operator messaging layer that keeps broadcasts, relay activity, and visible follow-up state in one place.
- Coordination-center messaging activity
- Relay and acknowledgement state
- Exceptions still surface for intervention
The ask for Lori
Day-one workflows
Is this the right first GCC replacement slice? Which two or three workflows have to work on day one?
Pilot failure points
Where would an early pilot fail first in the real world? What would break adoption?
Next stakeholders
Who else needs to believe in this for a tighter follow-up review or pilot path?